![ChatGPT vs Gemini vs Claude: Which AI Actually Wins in 2025? [Tested]](https://techdodo.in/storage/articles/chatgpt-vs-gemini-vs-claude-comparison-2025_1767105354_6953e34a08d8b_medium.webp)
Quick Answer: There's no single "best" AI in December 2025. Claude Opus 4.5 wins coding (80.9% SWE-bench), GPT-5.2 wins math (100% AIME 2025), and Gemini 3 Pro wins research (1501 LMArena Elo). For Indian users on a budget, Gemini AI Plus at ₹199/month offers the best value—or get it free with Jio.
Everyone's asking the wrong question.
"Which AI is the best?" assumes there's a single winner. But after testing GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro head-to-head across coding, writing, math, and research tasks, here's what I actually found: the model that wins depends entirely on what you're trying to do.
December 2025 was the most competitive stretch in AI history. Google dropped Gemini 3 on November 18, Anthropic fired back with Claude Opus 4.5 on November 24, and OpenAI—reportedly in "code red" mode—rushed out GPT-5.2 on December 11. Each claims to be the smartest. The benchmarks tell a more interesting story.

The Contenders: What Each Brings to the Fight
Before diving into who wins what, here's what you're actually choosing between:
Feature | ChatGPT (GPT-5.2) | Claude (Opus 4.5) | Gemini 3 Pro |
Release Date | Dec 11, 2025 | Nov 24, 2025 | Nov 18, 2025 |
Context Window | 400K tokens | 200K tokens | 1M tokens |
Knowledge Cutoff | Aug 2025 | Apr 2025 | Nov 2025 |
Best At | Math, reasoning, docs | Coding, writing, agents | Research, multimodal |
Here's the thing nobody's talking about: context window size matters more than most benchmarks for everyday use. Gemini's 1 million token window means you can upload an entire codebase. Claude's 200K handles most professional documents. GPT-5.2's 400K sits comfortably in between.
The Benchmarks That Actually Matter
Let's cut through the marketing. Here are the scores that predict real-world usefulness:
Benchmark | GPT-5.2 | Claude Opus 4.5 | Gemini 3 Pro | What It Measures |
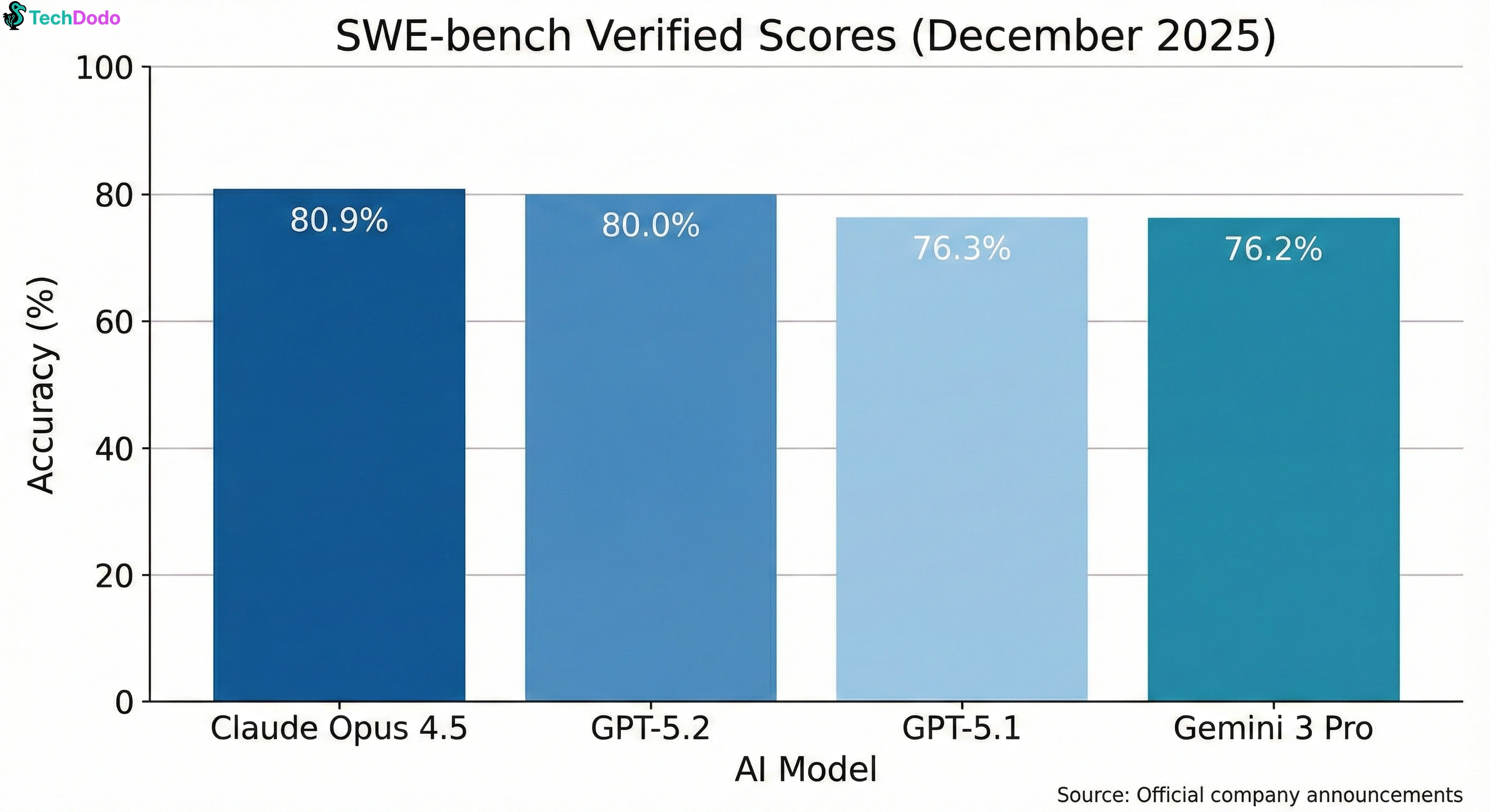
SWE-bench Verified | 80.0% | 80.9% ✅ | 76.2% | Real GitHub bug fixing |
AIME 2025 (no tools) | 100% ✅ | ~93% | 95% | Math competition problems |
ARC-AGI-2 | 52.9% ✅ | 37.6% | 31.1% | Abstract reasoning |
LMArena Elo | ~1480 | ~1470 | 1501 ✅ | Human preference voting |
GPQA Diamond | 93.2% | ~88% | 91.9% | PhD-level science |
Humanity's Last Exam | ~32% | ~30% | 37.5% ✅ | Cross-domain expertise |
Three different winners across six benchmarks. That's not a tie—it's evidence that each model genuinely excels at different things.
Claude's 80.9% on SWE-bench isn't just a number. It means when you give Claude a real GitHub issue from a real codebase, it fixes the bug correctly 4 out of 5 times. Anthropic claims it outperformed every human engineering candidate in their own hiring tests.
GPT-5.2's perfect 100% on AIME (without any coding tools) is genuinely unprecedented. If you're doing anything involving complex calculations, optimization, or mathematical reasoning, this matters.
Gemini 3 Pro breaking 1500 Elo on LMArena—the first model ever to do so—reflects something benchmarks can't fully capture: people consistently prefer its responses in blind testing.
Who Wins at What? The Practical Breakdown
Enough theory. Here's which model you should actually use for specific tasks:
Use Case | Winner | Why |
Coding & Debugging | Claude Opus 4.5 ✅ | 80.9% SWE-bench, best at multi-file projects |
Mathematical Reasoning | GPT-5.2 ✅ | 100% AIME 2025, 52.9% ARC-AGI-2 |
Creative Writing | Claude | Captures voice better, avoids AI clichés |
Research & Fact-checking | Gemini 3 Pro ✅ | Best grounded search, 1M token context |
Image Generation | ChatGPT ✅ | DALL-E 3 still leads for text rendering |
Deep Research Reports | ChatGPT | Generates comprehensive multi-page analyses |
Google Ecosystem | Gemini ✅ | Native Docs, Gmail, Drive integration |
Video Analysis | Gemini 3 Pro ✅ | 87.6% on Video-MMMU benchmark |
But here's what most comparison articles miss: the gap between these models is narrowing fast. A year ago, using the wrong model for a task felt painful. Now? The difference is often marginal for everyday use.
The India Pricing Reality Check
This is where it gets interesting for Indian users. The global AI wars have translated into aggressive local pricing:
Service | Free Tier | Budget | Standard | Premium |
ChatGPT | GPT-3.5 | Go ₹399/mo | Plus ₹1,999/mo | Pro ₹19,900/mo |
Claude | 30 msg/day Sonnet | — | Pro ~₹1,650/mo | Max ~₹8,300/mo |
Gemini | Unlimited basic | AI Plus ₹199/mo | AI Pro ₹1,950/mo | — |
But wait—the real value isn't in these prices. It's in the telecom deals:
Jio users: 18 months of Gemini Pro FREE (worth ₹35,100). You need a 5G plan at ₹349+ and initially must be 18-25, though this is expanding to all users.
Airtel users: 12 months of Perplexity Pro FREE (worth ₹17,000). All 360 million Airtel customers qualify.
ChatGPT Go: OpenAI is offering 12 months free for Indian users who sign up during the promotional period (normally ₹399/month).
The math is simple: if you're a Jio user, you're getting ₹35,100 worth of AI for the cost of your phone plan. That's hard to beat regardless of benchmark scores.
The Developer Angle: What Smart Devs Actually Do
Here's a pattern I've noticed among the most productive developers using AI in December 2025: they don't pick one model. They use a multi-model workflow:
Development Phase | Best Model | Why |
Research & Planning | Gemini 3 Pro | Best factual accuracy, grounded search |
Architecture Design | Claude Opus 4.5 | Catches edge cases others miss |
Rapid Prototyping | GPT-5.2 or Gemini | Fast, good enough for first drafts |
Complex Implementation | Claude (high effort) | 0% error rate on code editing benchmarks |
Math/Algorithm Work | GPT-5.2 exclusively | Nothing else comes close |
Documentation | Claude | Cleaner prose, better structure |
Claude Opus 4.5's dominance in agentic coding deserves special attention. It scores 62.3% on scaled tool use benchmarks—the next best model (also Claude, but older) scores 43.8%. For developers building AI agents that need to use multiple tools reliably, this gap is enormous.
Can We Crown a Single Winner? (The Honest Answer)
No. And that's actually good news for users.
The December 2025 benchmark reality:
- Gemini 3 Pro: #1 on LMArena (1501 Elo) and Humanity's Last Exam (37.5%)
- Claude Opus 4.5: #1 on SWE-bench coding (80.9%) and agentic tasks
- GPT-5.2: #1 on abstract reasoning ARC-AGI-2 (52.9%) and math (100% AIME)
If there was a clear winner, the others would be irrelevant. Instead, we have genuine competition—which means better models, lower prices, and more features for everyone.
The smartest users aren't asking "which is best?" They're asking "which is best for what I need today?"
The Verdict: Who Should Pick What
You Are... | Pick This | Because... |
Developer (enterprise) | Claude Pro | Best code accuracy, autonomous agents |
Developer (budget) | Gemini AI Plus | ₹199/mo, solid coding, 200GB storage |
Jio User | Gemini Pro (free) | ₹35,100 value at ₹0 for 18 months |
Airtel User | Perplexity Pro (free) | ₹17,000 value, great for research |
Student | Gemini (free tier) | Google offers free access for college students |
Content Creator | Claude | Best writing voice, captures style |
Researcher | Gemini 3 Pro | 1M context window, grounded search |
Power User (all tasks) | ChatGPT Plus | Most versatile, best memory system |
Casual User | ChatGPT Go | ₹399/mo (or free for 12 months), GPT-5 access |
Math/Finance | ChatGPT Pro | 100% AIME, best spreadsheet generation |
What's Coming Next (And Why It Matters)
December 2025 isn't the end—it's the beginning of a new phase. Here's what the roadmap suggests:
Early 2026: OpenAI is reportedly working on GPT-5.3 with improved image generation. Google's Gemini 3 Deep Think (already scoring 45.1% on ARC-AGI-2) will likely roll out more broadly.
The bigger picture: The real competition isn't between chatbots anymore—it's between AI agents that can accomplish complex tasks autonomously. Claude's lead on agentic benchmarks and Gemini's Antigravity coding platform suggest both companies see this as the future.
For Indian users specifically: expect more telecom partnerships. The Jio-Google and Airtel-Perplexity deals are just the beginning. India's 800 million internet users make it too important a market for any AI company to ignore.
Common Questions About ChatGPT, Gemini, and Claude
Is Claude better than ChatGPT for coding?
Yes, narrowly. Claude Opus 4.5 scores 80.9% on SWE-bench Verified versus GPT-5.2's 80.0%. The difference is marginal for most tasks, but Claude edges ahead on multi-file projects and agentic workflows.
Which AI is cheapest in India?
Gemini AI Plus at ₹199/month (promotional, first 6 months) is the cheapest paid tier. ChatGPT Go at ₹399/month is next. But Jio's free Gemini Pro offer (worth ₹35,100) and Airtel's free Perplexity Pro (worth ₹17,000) beat any paid subscription for value.
Can I use ChatGPT without a credit card in India?
Yes. OpenAI now supports UPI payments for Indian users. ChatGPT Go is also free for 12 months during the current promotional period.
Which AI has the largest context window?
Gemini 3 Pro with 1 million tokens—about 750,000 words. GPT-5.2 offers 400,000 tokens, Claude Opus 4.5 offers 200,000 tokens.
The AI wars benefit everyone watching from the sidelines. Three years ago, this level of AI capability didn't exist at any price. Today, you can access it for ₹199/month—or free with the right phone plan.
The "best" AI is the one that solves your specific problem. For everything else, there's always the free tier.




