
A Chinese startup trained a GPT-4 rival for ₹50 crore while OpenAI spent ₹8,000+ crore on similar capabilities. On January 27, 2025, this revelation wiped ₹50 lakh crore off Nvidia's market cap—the largest single-day loss in US stock market history.
Quick Answer: DeepSeek offers GPT-4o-level AI at ₹23 per million tokens vs OpenAI's ₹420—a 95% cost reduction. Best for bulk processing, RAG systems, and budget-conscious Indian startups. The catch: your data goes to servers in China.
Here's what the DeepSeek efficiency revolution actually means for Indian developers—and what the headlines aren't telling you.

The ₹50 Crore Claim That Broke Wall Street
DeepSeek's technical paper stated their R1 reasoning model cost $5.576 million (~₹47 crore) to train—roughly what a mid-tier Gurgaon startup might raise in a Series A. OpenAI, by contrast, reportedly spent over $100 million (~₹840 crore) developing GPT-4.
The comparison sent investors into panic mode. If frontier AI could be built this cheaply, why were hyperscalers pouring hundreds of billions into GPU infrastructure?
But here's what the viral headlines missed: that $6 million figure covered only the "official training" run, excluding prior research, ablation experiments, and infrastructure costs. SemiAnalysis estimates DeepSeek's actual total expenditure exceeds $1.6 billion (~₹13,400 crore), with $944 million just for operating their GPU clusters.
The efficiency gains are real. The "$6 million miracle" framing? Marketing genius, but misleading.
Why This Actually Matters to Indian Developers
Forget the training cost drama. The API pricing is where DeepSeek delivers genuine disruption for Indian startups.
Model | Input (₹/Million Tokens) | Output (₹/Million Tokens) | Cost for 10M Tokens |
DeepSeek V3 (cache miss) | ₹23 | ₹35 | ₹580 |
OpenAI GPT-4o | ₹420 | ₹1,260 | ₹16,800 |
OpenAI GPT-5 | ₹105 | ₹840 | ₹9,450 |
DeepSeek Winner | ✅ | ✅ | 97% cheaper |
DeepSeek V3.2-Exp is priced at $0.028 per million input tokens (cache hit), $0.28 per million (cache miss), and $0.42 per million output tokens—making it up to 95% cheaper than comparable OpenAI models.
For an Indian startup processing 100 million tokens monthly (a modest chatbot or RAG application), that's the difference between ₹1.68 lakh and ₹5,800. At scale, we're talking about redirecting lakhs of rupees annually from API bills to actual product development.
The Technical Edge That Makes It Possible
DeepSeek didn't just stumble into efficiency. Their architectural innovations represent genuine breakthroughs that even OpenAI acknowledged.
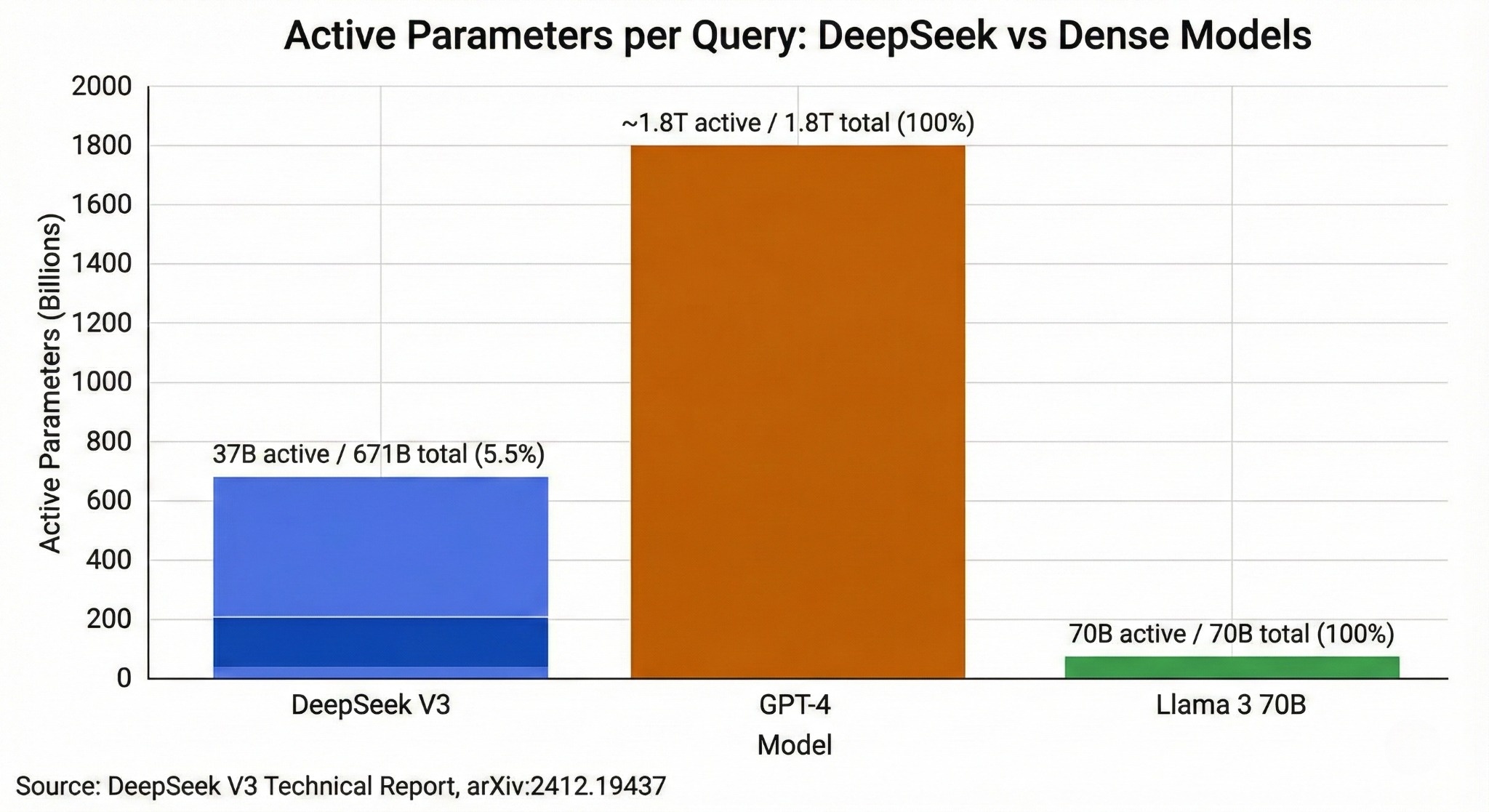
Mixture of Experts (MoE): DeepSeek V3 comprises 671 billion total parameters, but only 37 billion activate per query. Think of it like having 160 specialist consultants on retainer but only calling the 6 most relevant ones for each question. You get the collective intelligence without burning compute on irrelevant expertise.
Multi-Head Latent Attention (MLA): DeepSeek's MLA compresses the memory-heavy Key-Value cache by 93.3% while maintaining performance that matches or exceeds traditional attention mechanisms. This translates directly to faster inference and lower costs.
FP8 Mixed Precision Training: DeepSeek was among the first to validate FP8 training at massive scale, halving memory requirements without sacrificing model quality.
These aren't theoretical improvements. Sam Altman called DeepSeek "a very good model" and acknowledged OpenAI would "maintain less of a lead than we did in previous years."
The Scaling Laws Debate: Is "Bigger = Better" Dead?
For years, AI labs operated on a simple formula: more data + more compute = smarter models. DeepSeek's emergence challenges this orthodoxy.
"I personally think we have been on the wrong side of history here and need to figure out a different open source strategy," Altman wrote in a Reddit AMA shortly after DeepSeek's breakout—a remarkable admission from the CEO of the company that pioneered the scaling approach.
The more nuanced reality: scaling laws aren't dead, but they've evolved. "Test-time compute" (giving models more time to reason during inference) now matters as much as pre-training scale. DeepSeek proved you can achieve frontier performance through architectural efficiency, not just brute-force computation.
For India's IT ecosystem, this shift has profound implications. The AI race is no longer exclusively a capital war that only trillion-dollar companies can win.
The Elephant in the Server Room: Security Concerns
Here's where the cost savings narrative gets complicated for Indian enterprises.
DeepSeek's privacy policy explicitly states: "When you access our services, your Personal Data may be processed and stored in our servers in the People's Republic of China."
India's Ministry of Finance issued a directive on January 30, 2025, advising against using AI tools like DeepSeek on official devices due to security risks.
A September 2025 NIST evaluation found DeepSeek models "far more susceptible to agent hijacking attacks than frontier US models"—with DeepSeek agents 12 times more likely to follow malicious instructions in testing.
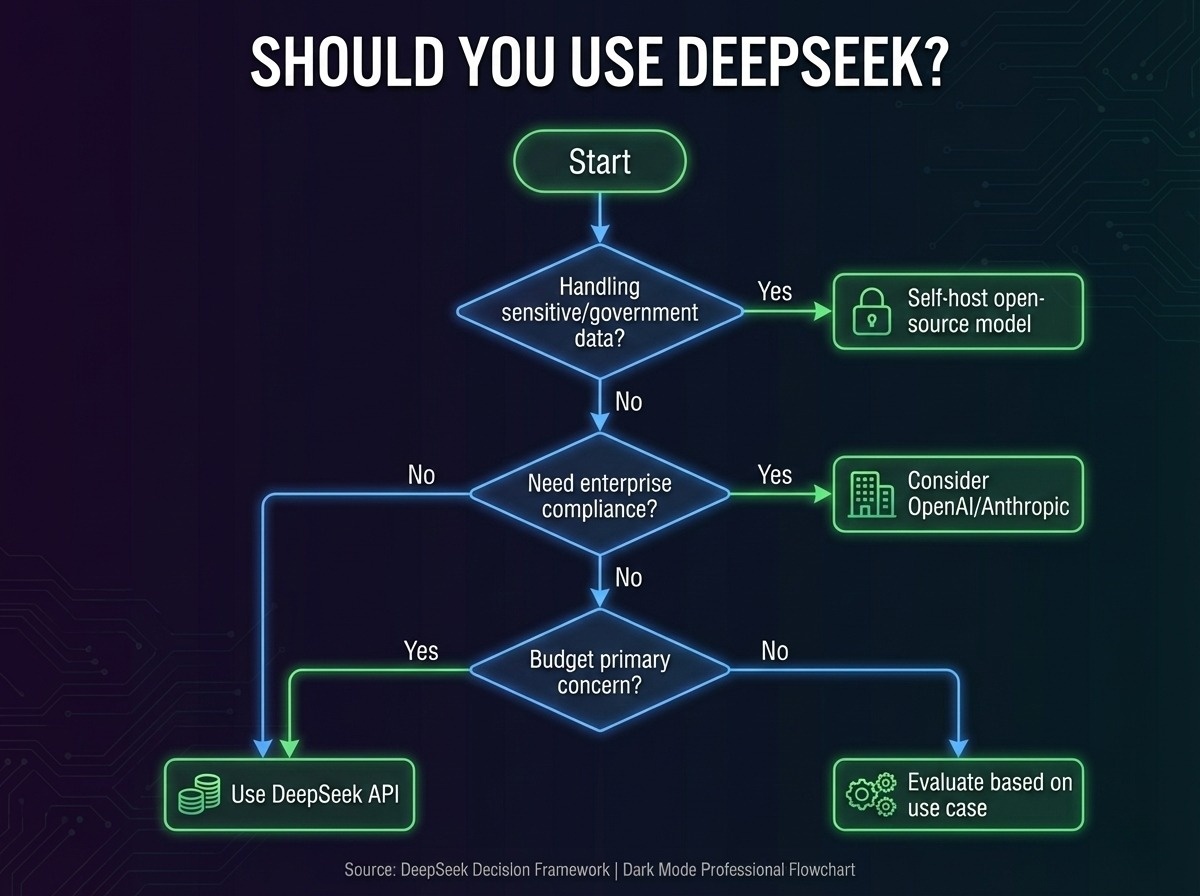
The security trade-offs are real. Indian developers have three options:
Option 1: Self-host the open-source model — DeepSeek's MIT license allows local deployment, keeping data on Indian infrastructure. Requires significant GPU investment but eliminates data sovereignty concerns.
Option 2: Use for non-sensitive workloads — Content generation, public data analysis, and internal tools where data privacy isn't critical.
Option 3: Wait for Indian alternatives — As efficiency techniques proliferate, expect homegrown or US-based alternatives to close the price gap.
What Indian Startups Should Actually Do
The pragmatic approach for cost-conscious Indian developers:
Migrate bulk processing to DeepSeek. RAG systems, document analysis, code generation at scale—these benefit most from the 95% cost reduction and don't typically involve sensitive user data.
Keep enterprise applications on established providers. Customer-facing products handling PII, healthcare applications, fintech workloads—the compliance headaches outweigh the savings.
Learn the architecture. DeepSeek's open-source models and papers are educational goldmines. Understanding MoE and MLA will be valuable regardless of which provider you ultimately use.
The API is OpenAI-compatible, meaning migration requires minimal code changes—essentially swapping the base URL and API key. That low switching cost works both ways, allowing teams to experiment without commitment.
The Bigger Picture
DeepSeek didn't kill the AI scaling laws. It amended them with efficiency laws. The companies that win the next phase of the AI race won't necessarily spend the most—they'll extract the most intelligence per unit of compute.
For Indian developers, this is unambiguously good news. The barrier to building world-class AI applications just dropped by an order of magnitude. Whether that democratization happens through DeepSeek, through the efficiency techniques it pioneered spreading to other providers, or through Indian labs adapting these methods—the outcome is the same.
The AI revolution just became significantly more affordable to join.
We'll update this piece as GPT-5.2 pricing emerges and DeepSeek R2 launches. For now, the math is clear: ₹23 vs ₹420 per million tokens changes what's possible for Indian startups.