
A Chinese startup spent $5.6 million training an AI model that wiped $600 billion off Nvidia in 12 hours. Wall Street panicked. Silicon Valley panicked. Indian investors watched Nifty IT bleed red.
Eleven months later, Nvidia hit all-time highs above $212.
Here's the thing: the market wasn't just wrong. It had the entire mental model backwards.
Quick Answer: DeepSeek R1, trained for ~$5.6M, caused Nvidia's $600B single-day crash on January 27, 2025. The panic was unfounded—efficient AI increases GPU demand via Jevons Paradox. Nvidia recovered to all-time highs by October 2025. For Indian investors: hold the line.
The $5.6 Million Bombshell That Shook Wall Street
On January 20, 2025, Hangzhou-based DeepSeek quietly released R1—an open-source reasoning model that matched OpenAI's o1 on math, coding, and logic benchmarks.
The kicker? DeepSeek V3 (the base model for R1) was trained on just 2,048 Nvidia H800 GPUs for approximately 2.79 million GPU hours. At $2/hour rental rates, that's roughly $5.6 million in compute costs.

Compare that to OpenAI's o1, estimated at $100+ million to train. Compare it to GPT-4, rumored at $50-100 million. DeepSeek built a comparable system for the cost of a nice Mumbai apartment.
But there's important nuance the headlines missed. That $5.6 million figure represents GPU rental hours for the final training run. It doesn't include research and development costs, failed experiments, or the infrastructure to house those GPUs. SemiAnalysis estimates DeepSeek's total server capital expenditure around $1.6 billion.
Still, the efficiency gains are real. DeepSeek's innovations—FP8 quantization, Multi-Head Latent Attention (MLA), and optimized load-balancing kernels—achieved remarkable results with constrained resources. They used export-restricted H800 chips (the "nerfed" version of H100s that China can legally access) and still produced a model that embarrassed Silicon Valley's billion-dollar moat assumptions.
The Historic Crash: DeepSeek Monday
January 27, 2025. A date that will live in market infamy.
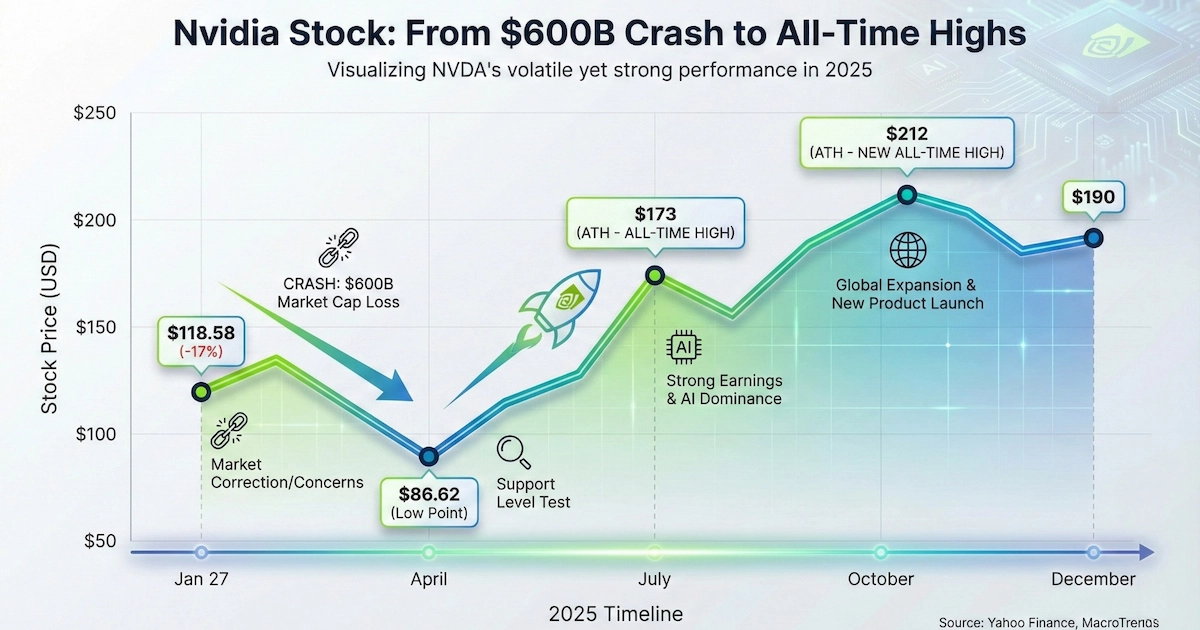
When U.S. markets opened, Nvidia shares went into freefall. By close of trading, the stock had plunged 17%—from $142.62 to $118.58.
Metric | January 27, 2025 |
Nvidia Opening | $142.62 |
Nvidia Close | $118.58 |
Single-Day Loss | -17% |
Market Cap Wiped | ~$600 billion |
Nasdaq Decline | -3.1% |
S&P 500 Decline | -1.85% |
Record Status | Largest single-day market cap loss in U.S. history ✅ |
$600 billion. Gone. In hours.
To put that in perspective: Nvidia lost more value in one trading session than the entire market cap of companies like Reliance Industries. Jensen Huang—Nvidia's leather-jacket-wearing CEO—watched nearly 20% of his personal net worth evaporate.
The contagion spread fast. AMD dropped 6%. Broadcom crashed 19%. TSMC fell 15%. In India, Nifty IT bled 3.35% as TCS, Infosys, Wipro, and HCL Tech all closed in the red.
The logic seemed sound: if DeepSeek could build frontier AI without expensive chips, why would anyone pay Nvidia's premium prices? The AI infrastructure thesis—that hyperscalers would spend hundreds of billions on GPUs—suddenly looked shaky.
But here's where it gets interesting...
Why the Market Got It Completely Wrong
Three weeks after the crash, Jensen Huang finally spoke publicly about DeepSeek. His message? The market's entire mental model was broken.
In a pre-recorded interview with DDN, Huang explained the fundamental misunderstanding that triggered the selloff.
The conventional wisdom assumed AI computing had two phases: pre-training (expensive, one-time) and inference (cheap, ongoing). If training got cheaper, the thinking went, you'd need fewer GPUs overall.
Huang called this paradigm "obviously wrong."
He pointed to what economists call Jevons Paradox—a principle from 1865 that explains why efficiency gains often increase resource consumption, not decrease it.
When steam engines became more efficient, coal consumption didn't fall. It exploded. Cheaper steam power made industrialization accessible to more factories, more industries, more applications. Total coal demand skyrocketed.
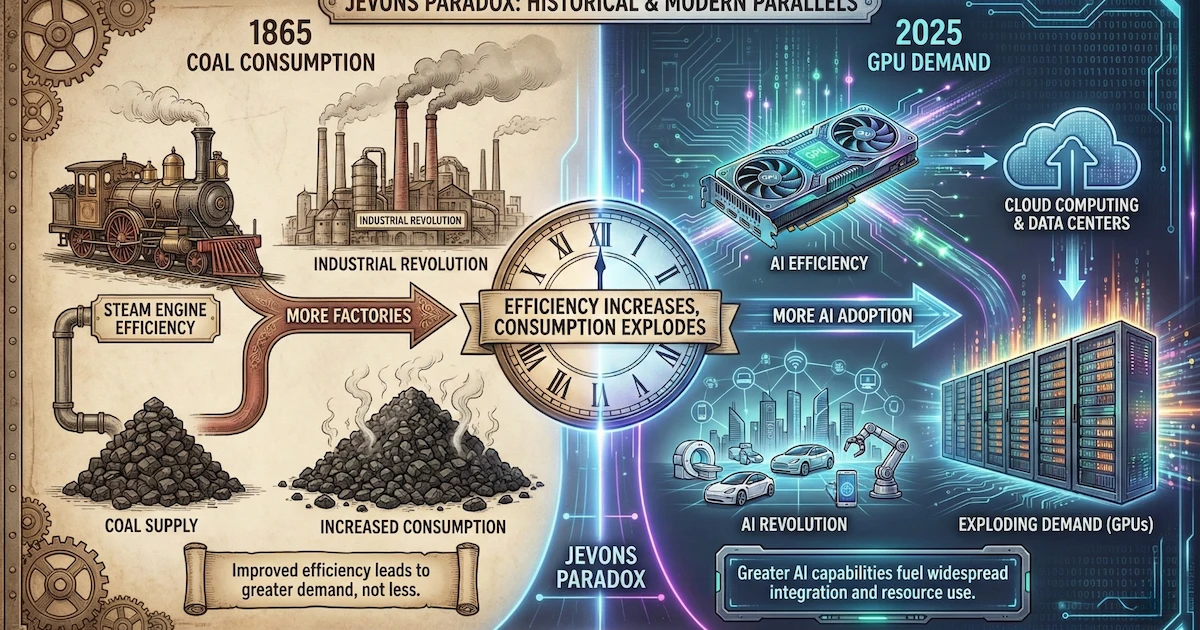
The same dynamic applies to AI. When DeepSeek proves you can train powerful models for $6 million instead of $100 million, what happens?
Startups that couldn't afford frontier AI suddenly can. Enterprises that were "waiting to see" now have no excuse. Universities, research labs, government agencies, developing nations—the floodgates open.
And all that new AI adoption requires inference compute. GPUs. Lots of them.
Microsoft CEO Satya Nadella captured it perfectly on X: "Jevons paradox strikes again! As AI gets more efficient and accessible, we will see its use skyrocket, turning it into a commodity we just can't get enough of."
The Vindication: Nvidia's Record Recovery
Want proof the market overreacted? Look at what happened next.
After the January crash, Nvidia's stock continued falling amid broader market concerns—touching a 52-week low of $86.62 in April 2025 as tariff wars rattled markets. Then came the recovery.
Date | Nvidia Stock Price | Milestone |
January 27, 2025 | $118.58 | DeepSeek crash close |
April 4, 2025 | $86.62 | 52-week low |
July 17, 2025 | $173.00 | New all-time high ✅ |
October 29, 2025 | $207.03 | Record closing high ✅ |
December 26, 2025 | $190.53 | Current price |
From the January crash low to October's peak, Nvidia rallied 79%. The stock that was supposedly "dead" because of DeepSeek hit all-time highs multiple times.
The analyst community remains aggressively bullish. Of 64 analysts covering Nvidia, 60 recommend buying. Price targets range from $140 to $352, with a consensus around $250. Bank of America, Wedbush, Citigroup, and Morgan Stanley all maintain Buy ratings.
Why the optimism? Three reasons keep appearing in analyst notes.
First, the Jevons Paradox thesis is playing out in real-time. Meta raised its 2025 AI capex guidance to $60-65 billion after DeepSeek's release—a 50% year-over-year increase. Microsoft, Google, and Amazon are doubling down, not pulling back.
Second, inference is becoming a bigger deal than training. DeepSeek's efficiency gains apply primarily to training. But running AI models at scale—inference—still requires massive GPU infrastructure. And that demand is accelerating.
Third, Nvidia's ecosystem moat runs deep. CUDA, their software platform, has over 4 million developers. Switching to AMD or custom silicon means rewriting codebases and retraining teams. That stickiness doesn't disappear because a Chinese startup trained a model cheaply.
What This Means for Indian Investors
Let's bring this home. If you're holding Nvidia, Indian IT stocks, or watching Indian AI startups—here's the practical breakdown.
Nvidia Holders in India
The January panic was a gift in disguise. Anyone who panic-sold at $118 missed a 79% rally to all-time highs. The Jevons Paradox thesis remains intact: efficient AI means more AI adoption, which means more GPU demand.
Current analyst consensus suggests 30-40% upside from present levels. The main risks aren't DeepSeek-related—they're geopolitical (China export controls, tariffs) and execution-focused (Blackwell chip supply constraints).
Nifty IT: TCS, Infosys, Wipro, HCL Tech
Indian IT took heat during the DeepSeek selloff, but analysts at Motilal Oswal (MOFSL) call it a net positive for the sector. Here's why:
When AI shifts from brute-force spending to cost-efficient implementation, the value chain changes. Tech giants move from the "build phase" (needing chips) to the "integrate phase" (needing services). Indian IT excels at integration, platform engineering, and enterprise deployment.
TCS is positioning itself as "the largest AI-led technology services provider." Infosys unveiled an AI-first GCC model with agentic AI solutions. Wipro is an early Agentic AI adopter for customer service and supply chains.
The Nifty IT index has been the worst performer of 2025 (down 10% YTD), but that's more about Trump tariffs, H1-B visa concerns, and weak discretionary spending than DeepSeek fears. The December recovery—Nifty IT is the top sectoral gainer this month—suggests the tide is turning.
Indian AI Startups: The DeepSeek Blueprint
For Krutrim, Sarvam AI, and other Indian AI startups, DeepSeek is validation that you don't need $100 million and 100,000 GPUs to build competitive AI.
The timing matters. Under the Biden administration's final AI chip export rules, India faced restrictions on high-end GPU imports starting May 2025. DeepSeek proves that export-restricted chips (H800s) can still produce frontier-class models with clever engineering.
The IndiaAI Mission is deploying 18,000+ GPUs—including 13,000 H100s—to startups like Sarvam AI, which is building India's first sovereign large language model. Krutrim deployed India's first GB200 system in March 2025 and is building Krutrim-2, a 12-billion-parameter multilingual model supporting 22 Indian languages.
Indian AI Startup | Status | GPU Access |
Krutrim | Unicorn ($1B valuation) | India's first GB200, 22-language LLM |
Sarvam AI | $53M Series A | 4,000 H100 GPUs via IndiaAI Mission |
Gnani AI | IndiaAI selected | Foundational model development |
Gan AI | IndiaAI selected | Video AI solutions |
DeepSeek's innovations—MLA, FP8 quantization, optimized kernels—are open-source. Indian engineers can study, adapt, and build upon them. The playbook for efficient AI development is now public.
The Developer Angle: What Makes DeepSeek Technically Special
For the tech-savvy readers, here's what made DeepSeek's efficiency possible.
Multi-Head Latent Attention (MLA): Instead of traditional attention mechanisms that scale quadratically with sequence length, MLA compresses key-value pairs into a latent space. This dramatically reduces memory requirements during inference.
FP8 Quantization: DeepSeek trained using 8-bit floating point precision instead of the standard 16-bit or 32-bit. This halves (or quarters) memory bandwidth and compute requirements with minimal accuracy loss.
Mixture of Experts (MoE) Architecture: DeepSeek V3 has 671 billion total parameters, but only 37 billion activate for any given task. It's like having a team of specialists where only the relevant experts engage. This sparsity is computationally efficient.
Distilled Open-Source Models: DeepSeek released distilled versions ranging from 1.5B to 70B parameters, fine-tuned on 800,000 reasoning samples generated by the full R1 model. The 32B distilled model outperforms OpenAI's o1-mini on multiple benchmarks.
Distilled Model | Parameters | Base Architecture | Can Run On |
DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | Qwen 2.5 | Consumer GPU (4GB VRAM) |
DeepSeek-R1-Distill-Llama-8B | 8B | Llama 3.1 | Gaming GPU (8GB VRAM) |
DeepSeek-R1-Distill-Qwen-32B | 32B | Qwen 2.5 | Workstation GPU (24GB VRAM) |
DeepSeek-R1-Distill-Llama-70B | 70B | Llama 3.3 | Multi-GPU or cloud |
For self-hosting enthusiasts: you can run the 8B model locally using Ollama with a single command: ollama run deepseek-r1:8b. Reasoning AI on your laptop. That's the democratization Jevons Paradox predicts.
Common Questions About DeepSeek R1
Is DeepSeek R1 safe to use for Indian users?
DeepSeek stores data on servers in China. Its privacy policy states it collects user inputs, chat history, and uploaded files. For sensitive business or personal use, consider self-hosting the open-source distilled models locally—they run on consumer hardware and keep data on your machine.
Can DeepSeek replace ChatGPT?
For reasoning-heavy tasks (math, coding, logic puzzles), DeepSeek R1 is competitive or superior. For creative writing, general conversation, or tasks requiring extensive world knowledge, ChatGPT remains more versatile. DeepSeek R1's API is also 20-50x cheaper—₹45 per million input tokens versus ₹2,500 for GPT-4o.
What's the price of Nvidia stock in India?
Nvidia (NVDA) trades on NASDAQ at ~$190 (approximately ₹16,150 at current exchange rates). Indian investors can access it through U.S. stock investing platforms like Vested, INDmoney, or interactive brokers. There's no direct NSE/BSE listing.
The Bigger Picture: AI's Sputnik Moment
Marc Andreessen called DeepSeek "AI's Sputnik moment"—a reference to when the Soviet Union's 1957 satellite launch shocked America into space race overdrive.
The analogy is apt. DeepSeek proves that export controls can't stop Chinese AI progress. Constraints breed innovation. When you can't get 100,000 H100s, you engineer around the limitation.
But Sputnik didn't end American space dominance. It accelerated it. Apollo happened because Sputnik was a wake-up call.
DeepSeek should be Silicon Valley's wake-up call. Brute-force scaling isn't the only path to powerful AI. Efficiency matters. Open-source collaboration matters. And the assumption that frontier AI requires Big Tech budgets is now empirically false.
For Indian tech, this is opportunity disguised as disruption. Efficient AI development means India's constrained GPU access is less of a handicap. The IndiaAI Mission's 18,000 GPUs can punch above their weight if engineers apply DeepSeek's lessons.
As Jaspreet Bindra, cofounder of AI&Beyond, put it: "DeepSeek is probably the best thing that happened to India. It gave us a kick in the backside to stop talking and start doing something."
What Happens Next
Nvidia isn't standing still. H200 chips are reportedly shipping to China from mid-February 2026 under new agreements. The Blackwell architecture is ramping production. Analyst price targets keep climbing—with some calling for $300+ by end of 2026.
The AI market is projected to grow at 37% CAGR through 2030. Nvidia's data center revenue hit $51.2 billion in Q3 2025 alone—up 93% year-over-year. The demand story remains intact.
For DeepSeek, the open-source momentum continues. They're releasing code repositories weekly, sharing research transparently, and proving that Chinese AI innovation is world-class—export controls notwithstanding.
The January crash was a stress test. The market failed it. Then corrected.
The lesson for Indian investors? Headlines create volatility. Understanding creates opportunity. Jevons Paradox isn't a theory anymore—it's playing out in real-time, quarter after quarter, as efficient AI drives explosive adoption.
The market's mental model was wrong. Make sure yours isn't.
We'll update this piece as Nvidia reports Q4 2025 earnings and DeepSeek releases V3.2. Bookmark for updates.